In this article, we will specifically look at RegExp in the QGIS tool.
RegEx is available from many parts in QGIS, here we will only be looking at it in manipulating values of the attribute table.
From the 'Select Feature using an Expression' dialog window, you should find group of 'String Functions'. This group contains functions that operates on strings (e.g., that replace, convert to upper case).
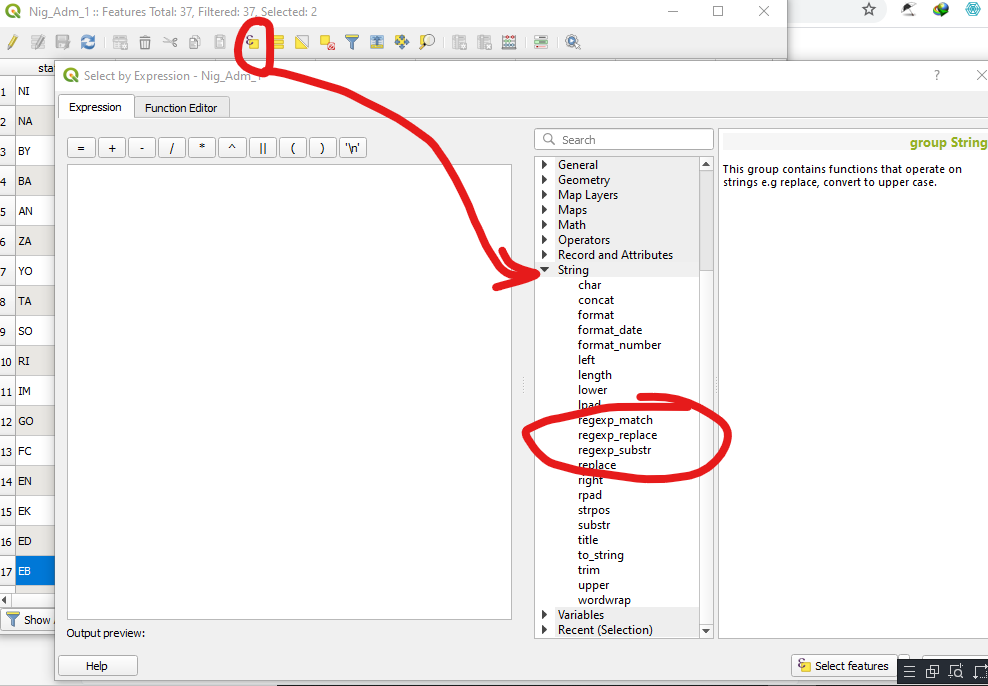
As you can see, there are three main functions with direct support for regular expression namely; regexp_match(), regexp_replace() and regexp_substr().
regexp_match
Returns the first matching position matching a regular expression within a string, or 0 if the substring is not found.
regexp_replace
Returns a string with the supplied regular expression replaced.
regexp_substr
Returns the portion of a string which matches a supplied regular expression.
Before we make use of any of these functions, we need to understand what regular expression is and why/where we need to or should use it.
What is regular expression?
As already stated above, it is a tool used to find complex pattern in a textual data. It is a sequence of characters used to describe a pattern in a string.
Lets say you want to find duplicate consecutive letters in a string. To do this manually, you would start searching like this: check for aa, bb, cc, dd, ee, ff, gg, ii, kk, .... xx, yy, zz. That is a lot of work right? Guess what, with regular expression it will take only a few seconds to write the expression and search for the pattern like this: (.)\1
That is how simple a regex is, just a sequence of characters as seen above that describes a pattern in a string. The example above (.)\1 will return any duplicate consecutive characters, we will look deeper in the coming section.
Regular Expression Engine
There are several engines for regular expressions and each flavor may have slightly different expression from the other.
QGIS, uses QT's QRegularExpression regular expression engine, which is itself just PCRE (Perl-Compatible Regular Expressions). You can read more about it and other engines on this wikipedia page.
Regular Expression Evaluator
Before you run your regular expression in QGIS it is a good idea you test or debug it using a professional tool made for this business and experiment with a friendly UI.
There are many online regex evaluator, the one I use often is: regex101.com
Load the website, select regex flavor and set the flags you want to use.

Building Blocks of a Regular Expression
To construct a regular expression pattern you need atleast one or combinations of the following:-
- Literals
- Character classes
- Boundary matchers
- Quantifiers
- Groups
- Operator
Literals
This is the most basic regex construct as it contain just the text/string pattern to search for. This would just be the actual string to be matched.
Assuming we want to search for 'un' in a string list that contain names of Nigeria states. The regex pattern will be to match for case sensitive literal characters 'un'. So, if you used uppercase literal characters 'UN' instead, you will get a different result unless you ignore case insensitive match flag.
Literals are the raw search string, see the explanation section on regex101 below.

In QGIS, let use the function like so: regexp_match("state_name" , 'un'). This will return same result as seen below, where three states are selected. Note that using uppercase 'UN' regexp_match("state_name" , 'UN') will also return different result.

1) Characters with special meaning
Note that some characters has special meaning in regex, and the use them as literals they most be escaped using '\'. See list of the such characters and there meaning below.
|
Character |
Meaning |
Escaped |
|
^ |
boundary matcher |
\^ |
|
$ |
boundary matcher |
\$ |
|
\ |
escape character |
\\ |
|
{ |
quantifier notation |
\{ |
|
} |
quantifier notation |
\} |
|
[ |
character class
notation |
\[ |
|
] |
character class
notation |
\] |
|
( |
group notation |
\( |
|
) |
group notation |
\) |
|
. |
predefined character
class |
\. |
|
* |
quantifier |
\* |
|
+ |
quantifier |
\+ |
|
? |
quantifier |
\? |
|
| |
OR operator |
\| |
As an example, if you want to search for '+34.78' in the string "Today’s temperature is +34.78 more when compared to that of last four years.". The regex will be: '\+34\.78' not '+34.78'.

2) Non-printable Characters
For non-printable character like the tab character ⇥ or a newline ↩ it is best to use the proper escape sequences for them:
|
Escape Sequence |
Meaning |
|
\t |
The tab character
(‘\u0009′) |
|
\n |
The newline (line
feed) character (‘\u000A’) |
|
\r |
The carriage-return
character (‘\u000D’) |
|
\s |
The space character
(‘\u0020’) |
Read more on the following topics (Character classes, Boundary matchers, Quantifiers, Groups and Operator) on this medium.com article: Everything you need to know about Regular Expressions
With this you should be ready to write regex in QGIS. Let take a look at some practical examples of working with regular expressions in QGIS.
Example RegEx in QGIS Attribute Table
1) Find duplicate consecutive characters
The dataset used here is the Nigeria states shapefile with attribute columns for state names and others as you will see in a moment.
Lets test run our 'duplicate consecutive characters' example.

Calling it on state name column in QGIS will also select "Kebbi and Cross River" states like this: regexp_match( "data_State", '([a-z])\\1' )

Similarly, we can find 'duplicate consecutive numbers' using: '([0-9])\1' on column "data_ID_2".

2) Find records ending with 4, 5, 6, 7, 8 or 9 in column "data_ID_1"
Same dataset used above will be used here.
Test run the expression in regex101.com will return 16 matches as seen below.

Doing same in QGIS using regexp_match( "data_ID_1", '[4-9]$' ) will match 16 results.

3) Make new columns for State and County names (Dataset...)
Here we will work with this US Census data to generate new attribute columns from existing column. In this case we have a column the contains both state and county name, and we will use regex to extract the state name and county name to different attribute columns.
The examples above made use of regexp_match(), now lets use regexp_replace() and regexp_substr() in this example because we want to interact with the match data not just the position.
Load the shapefile layer, you will see that there exist the 'NAME' column. We need to generate the 'county' and 'state' columns from 'NAME'.
From the 'NAME' records, we can see a pattern where the county name is separated from the state name by ', '. On this bases, we will use regular expression to extract the names.

As already mentioned above, we will use the regexp_substr() and regexp_replace() functions to complete this process by creating temporary columns using 'field calculator'.
For state name, we will select the every character from ', ' to the end. And then replace the unwanted ', ' character.

regexp_substr("NAME", ', .+$')
regexp_replace( "s_name", ', ', '')
For county name, we will select the every character from the beginning to ',' and replace 'County, ' with empty string.

regexp_substr("NAME", '.* ') OR regexp_substr("NAME", '.*,\\s')
regexp_replace( "c1_name", ', ', '' )
regexp_replace( "c2_name", ' County', '' )
That is it!
References
No comments:
Post a Comment