There are several python libraries available that allows the extraction of pdf data. Some notable once are listed below:-
1) PyPDF2
2) Tabula-py (requires JAVA installed)
3) Zamzar.com API
4) Camelot
5) TIKA
6) PDFMiner
All the above are great have there pros and cons which depends on the pdf file in question. You will need to try each one out to find out the one that works best for your specific case.
In my own case, TIKA has been the best so far for all the pdf I have worked with. So in this blog post, I will demonstrate how the 'tika' module is used to extract information from a pdf file.
Lets get started....
To install this module, you most has java 7 or above installed on your machine. Then using it is just as easy as this:-


That is it!
1) PyPDF2
2) Tabula-py (requires JAVA installed)
3) Zamzar.com API
4) Camelot
5) TIKA
6) PDFMiner
All the above are great have there pros and cons which depends on the pdf file in question. You will need to try each one out to find out the one that works best for your specific case.
In my own case, TIKA has been the best so far for all the pdf I have worked with. So in this blog post, I will demonstrate how the 'tika' module is used to extract information from a pdf file.
Lets get started....
To install this module, you most has java 7 or above installed on your machine. Then using it is just as easy as this:-
from tika import parser # pip install tika (need Java 7+ installed)
raw = parser.from_file('C:/Desktop/pdf_file_name.pdf')
print(raw['content'])
The content can then be stored in a variable for further manipulation.
Example
Lets extract the content of this PDF file:-

The result will look like this below. Note that I added .strip() function that will remove extra white spaces at the beginning and end of the content result.
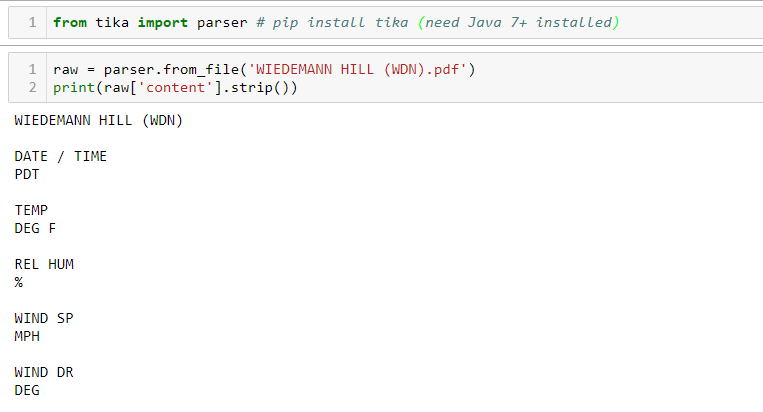

That is it!
No comments:
Post a Comment