Sometime back I had this "Combining multiple tabular data files together" situation at hand and I wrote about it then.
Now, there is another problem I have to solve.... It is similar to the above but not exactly the same. I will explain it below:-
The Problem
I have tow Data frames (tabular data) in which one is a subset of the other. That is to say second data frame (df2) is a subset of first data frame (df1).
Now, I need to merge them together based on a common column in the two data frames (df1 and df2) and also keep track of what row was in the main data frame and not in the subset data frame. This is more like saying:
- Remove rows from two Data frames that have uncommon column value
- To find rows in one data frame but not in another
- Find rows which don't exist in another data frame by multiple columns
Any how you look at it, above is the general idea!
The Solution
I solved this by using the pandas merge() method with the following flags/parameters: "how='left'" and "indicator=True".

This created a Data frame with an extra column name: _merge that contains two keywords 'both' (row contain in both data frames - df1 and df2) and 'left_only' (row contain in only the left data frames - df2).

Example:-
That is it!
Now, there is another problem I have to solve.... It is similar to the above but not exactly the same. I will explain it below:-
The Problem
Now, I need to merge them together based on a common column in the two data frames (df1 and df2) and also keep track of what row was in the main data frame and not in the subset data frame. This is more like saying:
- Remove rows from two Data frames that have uncommon column value
- To find rows in one data frame but not in another
- Find rows which don't exist in another data frame by multiple columns
Any how you look at it, above is the general idea!
The Solution
I solved this by using the pandas merge() method with the following flags/parameters: "how='left'" and "indicator=True".
This created a Data frame with an extra column name: _merge that contains two keywords 'both' (row contain in both data frames - df1 and df2) and 'left_only' (row contain in only the left data frames - df2).
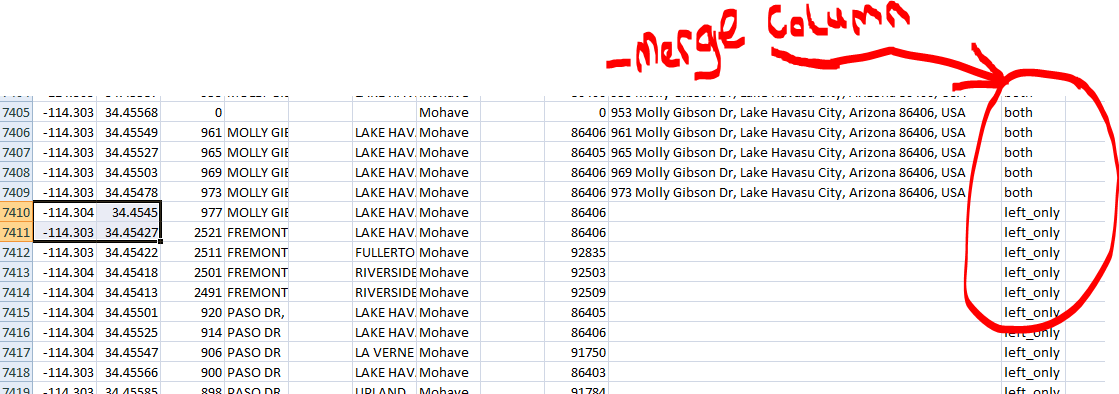
Example:-
df_all = df1.merge(df2.drop_duplicates(), on=['col1','col2'], how='left', indicator=True)
That is it!
No comments:
Post a Comment